diff --git a/README.md b/README.md
index 93dbb9ac353448813504c1f2c3d4853e62c2e24c..77d72c6418a69854a3ded3776b56b9780c0ffdf1 100644
--- a/README.md
+++ b/README.md
@@ -1,22 +1,22 @@
-<img src=https://raw.githubusercontent.com/tqchen/tvmlang.org/master/images/logo/tvm-logo-small.png width=128/> Open Deep Learning Compiler Stack
+<img src=https://raw.githubusercontent.com/tqchen/tvm.ai/master/images/logo/tvm-logo-small.png width=128/> Open Deep Learning Compiler Stack
==============================================
[](./LICENSE)
[](http://mode-gpu.cs.washington.edu:8080/job/dmlc/job/tvm/job/master/)
[Installation](docs/how_to/install.md) |
-[Documentation](http://docs.tvmlang.org) |
-[Tutorials](http://tutorials.tvmlang.org) |
+[Documentation](http://docs.tvm.ai) |
+[Tutorials](http://tutorials.tvm.ai) |
[Operator Inventory](topi) |
[FAQ](docs/faq.md) |
[Contributors](CONTRIBUTORS.md) |
-[Community](http://tvmlang.org/community.html) |
+[Community](http://tvm.ai/community.html) |
[Release Notes](NEWS.md)
TVM is a compiler stack for deep learning systems. It is designed to close the gap between the
productivity-focused deep learning frameworks, and the performance- and efficiency-focused hardware backends.
TVM works with deep learning frameworks to provide end to end compilation to different backends.
-Checkout the [tvm stack homepage](http://tvmlang.org/) for more information.
+Checkout the [tvm stack homepage](http://tvm.ai/) for more information.
License
-------
diff --git a/apps/howto_deploy/README.md b/apps/howto_deploy/README.md
index 6c732879a6a5b78cfc60a4f91cbdde8c77b0c233..570c42ed185d5e8023dce6e0ee747f662f99e319 100644
--- a/apps/howto_deploy/README.md
+++ b/apps/howto_deploy/README.md
@@ -8,4 +8,4 @@ Type the following command to run the sample code under the current folder(need
./run_example.sh
```
-Checkout [How to Deploy TVM Modules](http://docs.tvmlang.org/how_to/deploy.html) for more information.
+Checkout [How to Deploy TVM Modules](http://docs.tvm.ai/how_to/deploy.html) for more information.
diff --git a/docs/README.txt b/docs/README.txt
index b8780dd9fc870f0ae5def70fd7c51e742b34de0c..8f62dbacc58edcce4fff92b3d266352df4f49f07 100644
--- a/docs/README.txt
+++ b/docs/README.txt
@@ -1,6 +1,6 @@
The documentation of tvm is generated with recommonmark and sphinx.
-- A hosted version of doc is at http://docs.tvmlang.org
+- A hosted version of doc is at http://docs.tvm.ai
- pip install sphinx>=1.5.5 sphinx-gallery sphinx_rtd_theme matplotlib Image recommonmark
- Build tvm first in the root folder.
- To build locally, you need to enable USE_CUDA, USE_OPENCL, LLVM_CONFIG in config.mk and then type "make html" in this folder.
diff --git a/docs/dev/runtime.md b/docs/dev/runtime.md
index d601801a435e1f3ed29a452580af625904b4c15f..a5d8138c33724aace1aef1f0d9fb097723319bb5 100644
--- a/docs/dev/runtime.md
+++ b/docs/dev/runtime.md
@@ -3,7 +3,7 @@
TVM supports multiple programming languages for the compiler stack development and deployment.
In this note, we explain the key elements of the TVM runtime.
-
+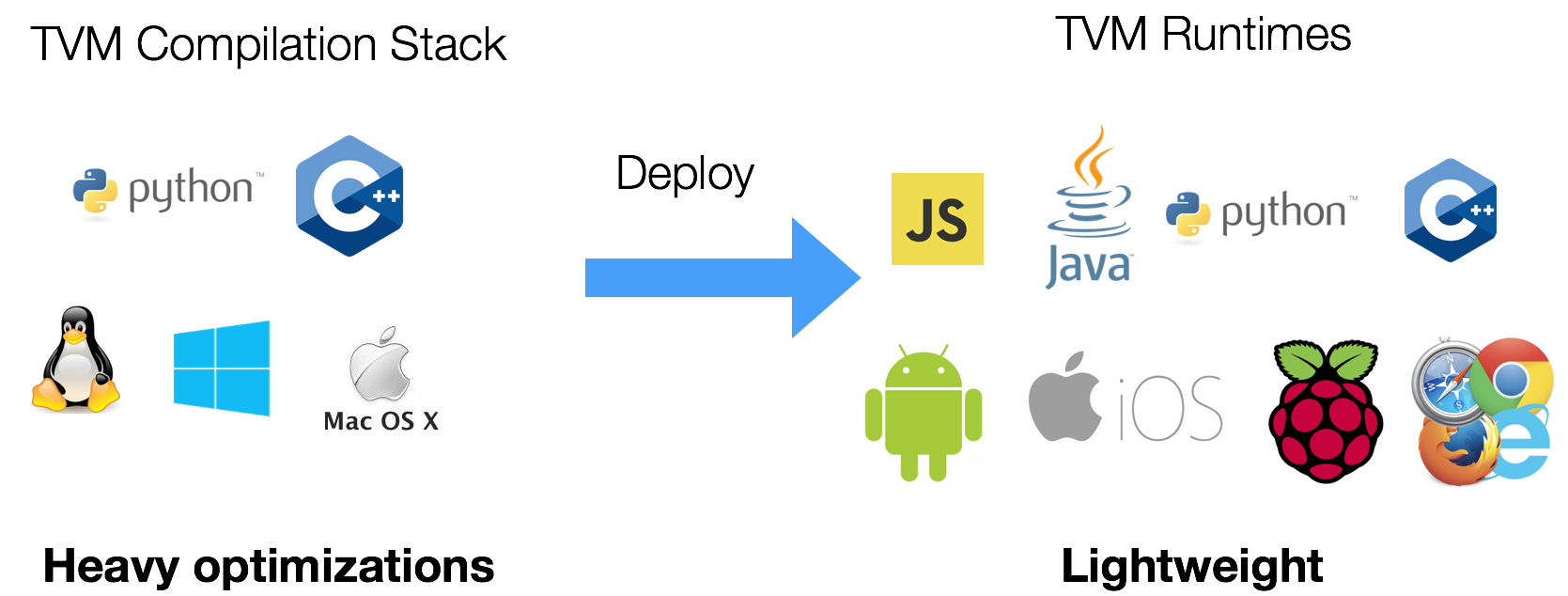
We need to satisfy quite a few interesting requirements
@@ -132,11 +132,11 @@ of new device easy, and we do not need to redo the host code generation for each
The PackedFunc and Module system also makes it easy to ship the function into remote devices directly.
Under the hood, we have an RPCModule that serializes the arguments to do the data movement and launches the computation on the remote.
-
+
The RPC server itself is minimum and can be bundled into the runtime. We can start a minimum TVM
RPC server on iPhone/android/raspberry pi or even the browser. The cross compilation on server and shipping of the module for testing can be done in the same script. Checkout
-[Cross compilation and RPC tutorial](http://docs.tvmlang.org/tutorials/deployment/cross_compilation_and_rpc.html#sphx-glr-tutorials-deployment-cross-compilation-and-rpc-py) for more details.
+[Cross compilation and RPC tutorial](http://docs.tvm.ai/tutorials/deployment/cross_compilation_and_rpc.html#sphx-glr-tutorials-deployment-cross-compilation-and-rpc-py) for more details.
This instant feedback gives us a lot of advantages. For example, to test the correctness of generated code on iPhone, we no longer have to write test-cases in swift/objective-c from scratch -- We can use RPC to execute on iPhone, copy the result back and do verification on the host via numpy. We can also do the profiling using the same script.
diff --git a/docs/how_to/deploy.md b/docs/how_to/deploy.md
index 68630adfaeaaefcb925219b5ff72b948961c9ca4..69fedaa974b424d2eb704a1fd11323b2b86f664d 100644
--- a/docs/how_to/deploy.md
+++ b/docs/how_to/deploy.md
@@ -12,7 +12,7 @@ cd apps/howto_deploy
Get TVM Runtime Library
-----------------------
-
+
The only thing we need is to link to a TVM runtime in your target platform.
TVM provides a minimum runtime, which costs around 300K to 600K depending on how much modules we use.
@@ -64,7 +64,7 @@ From android java TVM API to load model & execute can be refered at this [java](
Deploy NNVM Modules
-------------------
NNVM compiled modules are fully embedded in TVM runtime as long as ```GRAPH_RUNTIME``` option
-is enabled in tvm runtime. Check out the [TVM documentation](http://docs.tvmlang.org/) for
+is enabled in tvm runtime. Check out the [TVM documentation](http://docs.tvm.ai/) for
how to deploy TVM runtime to your system.
In a nutshell, we will need three items to deploy a compiled module.
diff --git a/jvm/README.md b/jvm/README.md
index 0a113fed0e7bb13e72f2ef547faa33c2a3d78c11..2438758617a647a29b96532e2684dfbd92662608 100644
--- a/jvm/README.md
+++ b/jvm/README.md
@@ -27,7 +27,7 @@ TVM4J contains three modules:
### Build
-First please refer to [Installation Guide](http://docs.tvmlang.org/how_to/install.html) and build runtime shared library from the C++ codes (libtvm\_runtime.so for Linux and libtvm\_runtime.dylib for OSX).
+First please refer to [Installation Guide](http://docs.tvm.ai/how_to/install.html) and build runtime shared library from the C++ codes (libtvm\_runtime.so for Linux and libtvm\_runtime.dylib for OSX).
Then you can compile tvm4j by
@@ -117,12 +117,12 @@ public class LoadAddFunc {
Module fadd = Module.load(loadingDir + File.separator + "add_cpu.so");
TVMContext ctx = TVMContext.cpu();
-
+
long[] shape = new long[]{2};
NDArray arr = NDArray.empty(shape, ctx);
arr.copyFrom(new float[]{3f, 4f});
NDArray res = NDArray.empty(shape, ctx);
-
+
fadd.entryFunc().pushArg(arr).pushArg(arr).pushArg(res).invoke();
System.out.println(Arrays.toString(res.asFloatArray()));
@@ -135,7 +135,7 @@ public class LoadAddFunc {
## RPC Server
-There are two ways to start an RPC server on JVM. A standalone server can be started by
+There are two ways to start an RPC server on JVM. A standalone server can be started by
```java
Server server = new Server(port);
diff --git a/nnvm/README.md b/nnvm/README.md
index b733f4f852eb64e54ec5c237a82c10a9d9f81d47..ed8a18e3fa1e0ffb6af6da23a6ce7fdfdd273a3c 100644
--- a/nnvm/README.md
+++ b/nnvm/README.md
@@ -1,23 +1,4 @@
-# NNVM: Open Compiler for AI Frameworks
-[](http://mode-gpu.cs.washington.edu:8080/job/dmlc/job/nnvm/job/master/)
-[](./LICENSE)
-
-[Installation](docs/how_to/install.md) |
-[Documentation](http://nnvm.tvmlang.org) |
-[Tutorials](http://nnvm.tvmlang.org/tutorials/index.html) |
-[Release Notes](NEWS.md)
-
-NNVM compiler offers reusable computation graph optimization and compilation for deep learning systems.
-It is backed by the [TVM stack](http://tvmlang.org) and provides modules to:
-
-- Represent deep learning workloads from front-end frameworks via a graph IR.
-- Optimize computation graphs to improve performance.
-- Compile into executable modules and deploy to different hardware backends with minimum dependency.
-
-NNVM is designed to add new frontend, operators and graph optimizations in a decentralized fashion without changing the core interface.
-The compiled module can be deployed to server, mobile, embedded devices and browsers with minimum dependency, in languages including c++, python, javascript, java, objective-c. Checkout [our release announcement](http://www.tvmlang.org/2017/10/06/nnvm-compiler-announcement.html)
-
-The following code snippet demonstrates the general workflow of nnvm compiler.
+# NNVM Compiler Module of TVM Stack
```python
import tvm
@@ -52,13 +33,3 @@ rmodule = graph_runtime.create(graph, rlib, remote.gpu(0))
rmodule.set_input(**params)
rmodule.run()
```
-
-License
--------
-Licensed under an [Apache-2.0](https://github.com/dmlc/nnvm/blob/master/LICENSE) license.
-
-
-Links
------
-- [TinyFlow](https://github.com/tqchen/tinyflow) on how you can use NNVM to build a TensorFlow like API.
-- [Apache MXNet](http://mxnet.io/) uses NNVM as a backend.
diff --git a/tutorials/nnvm/deploy_model_on_mali_gpu.py b/tutorials/nnvm/deploy_model_on_mali_gpu.py
index 3c0152b8c19955e65f0bb8d53557f91d5359f43e..116e99f7679040a5d81d0885d6ecf7b15c346bd6 100644
--- a/tutorials/nnvm/deploy_model_on_mali_gpu.py
+++ b/tutorials/nnvm/deploy_model_on_mali_gpu.py
@@ -7,8 +7,7 @@ This is an example of using NNVM to compile a ResNet model and
deploy it on Firefly-RK3399 with ARM Mali GPU. We will use the
Mali-T860 MP4 GPU on this board to accelerate the inference.
-This tutorial is based on the `tutorial <http://nnvm.tvmlang.org/tutorials/deploy_model_on_rasp.html>`_
-for deploying on Raspberry Pi by `Ziheng Jiang <https://ziheng.org/>`_.
+This tutorial is based on the tutorial for deploying on Raspberry Pi by `Ziheng Jiang <https://ziheng.org/>`_.
Great thanks to the original author, I only do several lines of modification.
To begin with, we import nnvm (for compilation) and TVM (for deployment).