
How to Deploy Compiled Modules
We provide an example on how to deploy TVM modules in apps/howto_deploy
To run the example, you can use the following command
cd apps/howto_deploy
./run_example.shGet TVM Runtime Library
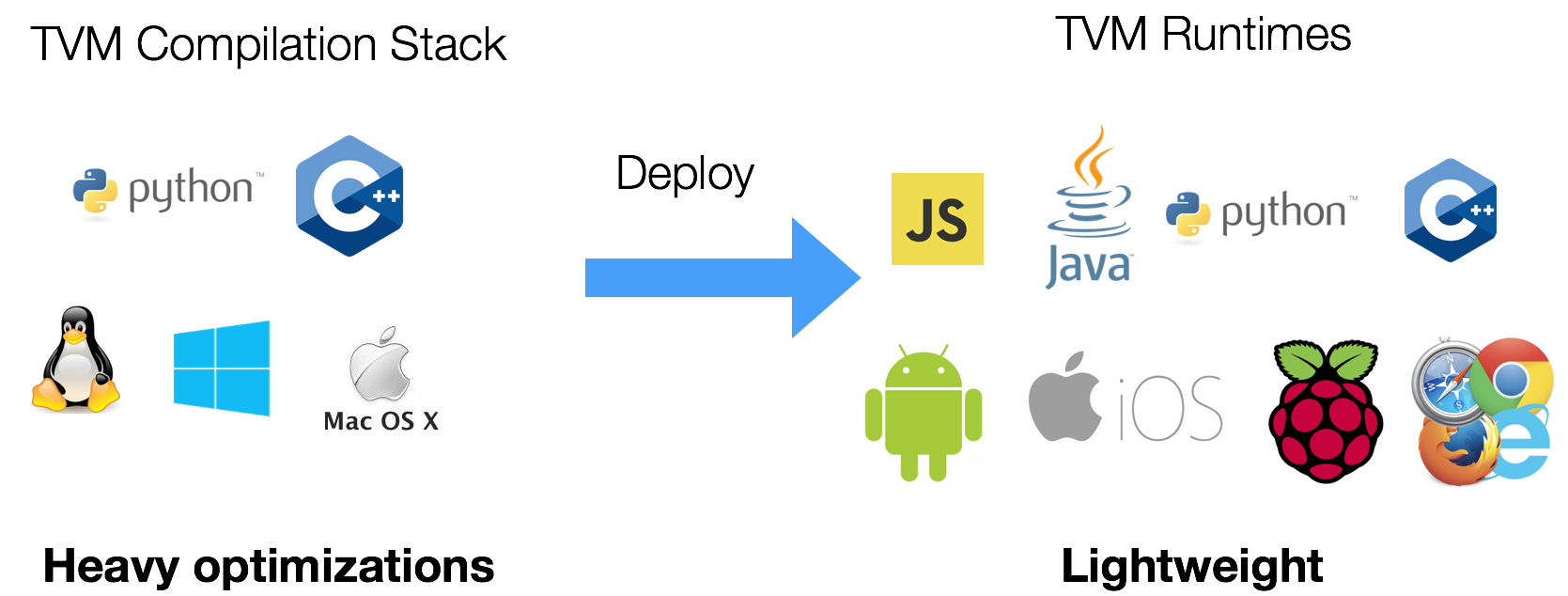
The only thing we need is to link to a TVM runtime in your target platform.
TVM provides a minimum runtime, which costs around 300K to 600K depending on how much modules we use.
In most cases, we can use libtvm_runtime.so that comes with the build.
If somehow you find it is hard to build libtvm_runtime, checkout tvm_runtime_pack.cc.
It is an example all in one file that gives you TVM runtime.
You can compile this file using your build system and include this into your project.
You can also checkout apps for example applications build with TVM on iOS, Android and others.
Dynamic Library vs. System Module
TVM provides two ways to use the compiled library. You can checkout prepare_test_libs.py on how to generate the library and cpp_deploy.cc on how to use them.
- Store library as a shared library and dynamically load the library into your project.
- Bundle the compiled library into your project in system module mode.
Dynamic loading is more flexible and can load new modules on the fly. System module is a more static approach. We can use system module in places where dynamic library loading is banned.
Deploy to Android
Build model for Android Target
NNVM compilation of model for android target could follow same approach like android_rpc.
An reference exampe can be found at chainer-nnvm-example
Above example will directly run the compiled model on RPC target. Below modification at rum_mobile.py will save the compilation output which is required on android target.
lib.export_library("deploy_lib.so", ndk.create_shared)
with open("deploy_graph.json", "w") as fo:
fo.write(graph.json())
with open("deploy_param.params", "wb") as fo:
fo.write(nnvm.compiler.save_param_dict(params))deploy_lib.so, deploy_graph.json, deploy_param.params will go to android target.
TVM Runtime for Android Target
Refer here to build CPU/OpenCL version flavor TVM runtime for android target. From android java TVM API to load model & execute can be refered at this java sample source.
Deploy NNVM Modules
NNVM compiled modules are fully embedded in TVM runtime as long as GRAPH_RUNTIME option
is enabled in tvm runtime. Check out the TVM documentation for
how to deploy TVM runtime to your system.
In a nutshell, we will need three items to deploy a compiled module. Checkout our tutorials on getting started with NNVM compiler for more details.
- The graph json data which contains the execution graph.
- The tvm module library of compiled functions.
- The parameter blobs for stored parameters.
We can then use TVM's runtime API to deploy the compiled module. Here is an example in python.
import tvm
# tvm module for compiled functions.
loaded_lib = tvm.module.load("deploy.so")
# json graph
loaded_json = open(temp.relpath("deploy.json")).read()
# parameters in binary
loaded_params = bytearray(open(temp.relpath("deploy.params"), "rb").read())
fcreate = tvm.get_global_func("tvm.graph_runtime.create")
ctx = tvm.gpu(0)
gmodule = fcreate(loaded_json, loaded_lib, ctx.device_type, ctx.device_id)
set_input, get_output, run = gmodule["set_input"], gmodule["get_output"], gmodule["run"]
set_input("x", tvm.nd.array(x_np))
gmodule["load_params"](loaded_params)
run()
out = tvm.nd.empty(shape)
get_output(0, out)
print(out.asnumpy())An example in c++.
#include <dlpack/dlpack.h>
#include <tvm/runtime/module.h>
#include <tvm/runtime/registry.h>
#include <tvm/runtime/packed_func.h>
#include <fstream>
#include <iterator>
#include <algorithm>
int main()
{
// tvm module for compiled functions
tvm::runtime::Module mod_syslib = tvm::runtime::Module::LoadFromFile("deploy.so");
// json graph
std::ifstream json_in("deploy.json", std::ios::in);
std::string json_data((std::istreambuf_iterator<char>(json_in)), std::istreambuf_iterator<char>());
json_in.close();
// parameters in binary
std::ifstream params_in("deploy.params", std::ios::binary);
std::string params_data((std::istreambuf_iterator<char>(params_in)), std::istreambuf_iterator<char>());
params_in.close();
// parameters need to be TVMByteArray type to indicate the binary data
TVMByteArray params_arr;
params_arr.data = params_data.c_str();
params_arr.size = params_data.length();
int dtype_code = kDLFloat;
int dtype_bits = 32;
int dtype_lanes = 1;
int device_type = kDLCPU;
int device_id = 0;
// get global function module for graph runtime
tvm::runtime::Module mod = (*tvm::runtime::Registry::Get("tvm.graph_runtime.create"))(json_data, mod_syslib, device_type, device_id);
DLTensor* x;
int in_ndim = 4;
int64_t in_shape[4] = {1, 3, 224, 224};
TVMArrayAlloc(in_shape, in_ndim, dtype_code, dtype_bits, dtype_lanes, device_type, device_id, &x);
// load image data saved in binary
std::ifstream data_fin("cat.bin", std::ios::binary);
data_fin.read(static_cast<char*>(x->data), 3 * 224 * 224 * 4);
// get the function from the module(set input data)
tvm::runtime::PackedFunc set_input = mod.GetFunction("set_input");
set_input("data", x);
// get the function from the module(load patameters)
tvm::runtime::PackedFunc load_params = mod.GetFunction("load_params");
load_params(params_arr);
// get the function from the module(run it)
tvm::runtime::PackedFunc run = mod.GetFunction("run");
run();
DLTensor* y;
int out_ndim = 1;
int64_t out_shape[1] = {1000, };
TVMArrayAlloc(out_shape, out_ndim, dtype_code, dtype_bits, dtype_lanes, device_type, device_id, &y);
// get the function from the module(get output data)
tvm::runtime::PackedFunc get_output = mod.GetFunction("get_output");
get_output(0, y);
// get the maximum position in output vector
auto y_iter = static_cast<float*>(y->data);
auto max_iter = std::max_element(y_iter, y_iter + 1000);
auto max_index = std::distance(y_iter, max_iter);
std::cout << "The maximum position in output vector is: " << max_index << std::endl;
TVMArrayFree(x);
TVMArrayFree(y);
return 0;
}